Given a Corpus of a Review Split It in Terms Sentences
This commodity was published as a part of the Data Science Blogathon.
Introduction
Artificial intelligence has been improved tremendously without needing to alter the underlying hardware infrastructure. Users can run an Artificial intelligence plan in an old calculator organisation. On the other hand, the casher effect of motorcar learning is unlimited. Natural Language Processing is i of the branches of AI that gives the machines the ability to read, understand, and deliver meaning. NLP has been very successful in healthcare, media, finance, and man resource.
The near common form of unstructured data is texts and speeches. It'southward plenty but hard to excerpt useful information. If not, it would take a long time to mine the data. Written text and speech incorporate rich information. It's considering we, equally intelligent beings, utilise writing and speaking as the chief grade of communication. NLP can analyze these data for u.s. and do the task similar sentiment analysis, cognitive assistant, bridge filtering, identifying faux news, and real-fourth dimension language translation.
This commodity will cover how NLP understands the texts or parts of speech. Mainly we will be focusing on Words and Sequence Analysis. Information technology includes text nomenclature, vector semantic and word embedding, probabilistic language model, sequential labeling, and speech reorganization. Nosotros will look at the sentiment analysis of fifty grand IMDB pic reviewer. Our goal is to identify whether the review posted on the IMDB site past its user is positive or negative.
Topic List
- Understand what NLP is?
- What does NLP use for?
- Words and Sequences
- Text nomenclature
- Vector Semantic and Word embedding
- Probabilistic Language Models
- Sequence labeling
- Parsers
- Semantics
- Performing Semantic Analysis on IMDB moving-picture show review information projection
NLP has widely used in cars, smartphones, speakers, computers, websites, etc. Google Translator usage machine translator which is the NLP organization. Google Translator wrote and spoken natural linguistic communication to desire language users want to translate. NLP helps google translator to sympathize the word in context, remove extra noises, and build CNN to understand native voice.
NLP is also popular in chatbots. Chatbots is very useful because information technology reduces the human work of asking what customer needs. NLP chatbot cans ask sequential questions like what the user problem is and where to find the solution. Apple and AMAZON have a robust chatbot in their system. When the user asks some questions, the chatbot converts them into understandable phrases in the internal system.
It'south phone call toke. Then token goes into NLP to get the idea of what users are request. NLP is used in information retrieval (IR). IR is a software program that deals with big storage, evaluation of data from large text documents from repositories. Information technology volition retrieve only relevant information. For example, it is used in google voice detection to trim unnecessary words.
Awarding of NLP
- Machine Translation i.e. Google Translator
- Information retrieval
- Question Answering i.e. ChatBot
- Summarization
- Sentiment Analysis
- Social Media Analysis
- Mining large data\
Words and Sequences
NLP system needs to understand text, sign, and semantic properly. Many methods help the NLP system to empathise text and symbols. They are text classification, vector semantic, discussion embedding, probabilistic linguistic communication model, sequence labeling, and spoken language reorganization.
-
Text classification
Text clarification is the process of categorizing the text into a group of words. Past using NLP, text classification can automatically analyze text and so assign a fix of predefined tags or categories based on its context. NLP is used for sentiment assay, topic detection, and linguistic communication detection. At that place is mainly three text classification arroyo-
- Rule-based System,
- Machine System
- Hybrid Organization.
In the dominion-based arroyo, texts are separated into an organized group using a set of handicraft linguistic rules. Those handicraft linguistic rules comprise users to define a list of words that are characterized by groups. For example, words like Donald Trump and Boris Johnson would be categorized into politics. People similar LeBron James and Ronaldo would be categorized into sports.
Automobile-based classifier learns to make a classification based on past observation from the information sets. User information is prelabeled equally tarin and test information. It collects the nomenclature strategy from the previous inputs and learns continuously. Auto-based classifier usage a bag of a word for feature extension.
In a bag of words, a vector represents the frequency of words in a predefined dictionary of a word listing. We tin can perform NLP using the post-obit machine learning algorithms: Naïve Bayer, SVM, and Deep Learning.
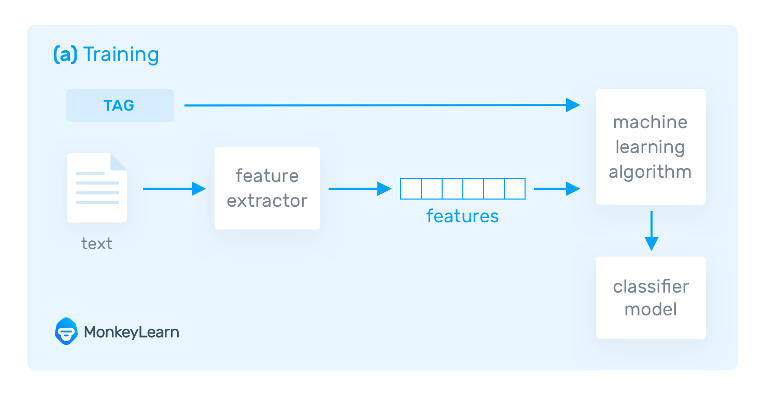
The third approach to text nomenclature is the Hybrid Approach. Hybrid arroyo usage combines a dominion-based and automobile Based approach. Hybrid based approach usage of the rule-based system to create a tag and utilize car learning to railroad train the system and create a rule. Then the machine-based rule list is compared with the rule-based rule list. If something does not match on the tags, humans ameliorate the listing manually. It is the best method to implement text classification
-
Vector Semantic
Vector Semantic is another way of word and sequence analysis. Vector semantic defines semantic and interprets words meaning to explain features such as similar words and opposite words. The master idea backside vector semantic is ii words are akin if they have used in a similar context. Vector semantic divide the words in a multi-dimensional vector space. Vector semantic is useful in sentiment analysis.
-
Discussion Embedding
Word embedding is another method of give-and-take and sequence analysis. Embedding translates spares vectors into a low-dimensional infinite that preserves semantic relationships. Word embedding is a type of discussion representation that allows words with similar meaning to have a similar representation. There are 2 types of word embedding-
- Word2vec
- Doc2Vec.
Word2Vec is a statistical method for effectively learning a standalone discussion embedding from a text corpus.
Doc2Vec is similar to Doc2Vec, only it analyzes a group of text like pages.
-
Probabilistic Linguistic communication Model
Another arroyo to give-and-take and sequence analysis is the probabilistic language model. The goal of the probabilistic language model is to calculate the probability of a judgement of a sequence of words. For example, the probability of the discussion "a" occurring in a given give-and-take "to" is 0.00013131 percent.
-
Sequence Labeling
Sequence labeling is a typical NLP task that assigns a class or label to each token in a given input sequence. If someone says "play the movie by tom hanks". In sequence, labeling will be [play, movie, tom hanks]. Play determines an activity. Movies are an case of activity. Tom Hanks goes for a search entity. Information technology divides the input into multiple tokens and uses LSTM to clarify it. There are 2 forms of sequence labeling. They are token labeling and span labeling.
Parsing is a phase of NLP where the parser determines the syntactic structure of a text by analyzing its constituent words based on an underlying grammer. For case, "tom ate an apple" will be divided into proper noun tom, verb ate, determiner , noun apple. The best example is Amazon Alexa.
We talk over how text is classified and how to separate the word and sequence so that the algorithm tin can understand and categorize it. In this project, nosotros are going to observe a sentiment analysis of l thousand IMDB moving-picture show reviewer. Our goal is to place whether the review posted on the IMDB site past its user is positive or negative.
This project covers text mining techniques similar Text Embedding, Bags of Words, word context, and other things. We will also cover the introduction of a bidirectional LSTM sentiment classifier. We volition also look at how to import a labeled dataset from TensorFlow automatically. This project also covers steps like data cleaning, text processing, data balance through sampling, and train and test a deep learning model to allocate text.
Parsing
Parser determines the syntactic structure of a text by analyzing its constituent words based on an underlying grammer. It divides group words into component parts and separates words.
For more details about parsing, cheque this article.
Semantic
Text is at the center of how we communicate. What is really hard is understanding what is beingness said in written or spoken conversation? Understanding lengthy articles and books are even more hard. Semantic is a process that seeks to understand linguistic meaning by amalgam a model of the principle that the speaker uses to convey pregnant. It's has been used in client feedback assay, article analysis, imitation news detection, Semantic analysis, etc.
Instance Awarding
Hither is the code Sample:
Importing necessary library
# It is divers past the kaggle/python Docker image: https://github.com/kaggle/docker-python # For example, here's several helpful packages to load import numpy as np # linear algebra import pandas as pd # information processing, CSV file I/O (e.g. pd.read_csv) # Input data files are available in the read-but "../input/" directory # For instance, running this (by clicking run or pressing Shift+Enter) will listing all files under the input directory import os for dirname, _, filenames in os.walk('/kaggle/input'): for filename in filenames: print(os.path.join(dirname, filename)) # You tin write upward to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All" # You can besides write temporary files to /kaggle/temp/, simply they won't be saved outside of the current session #Importing require Libraries import os import matplotlib.pyplot as plt import nltk from tkinter import * import seaborn as sns import matplotlib.pyplot as plt sns.set() import scipy import tensorflow as tf import tensorflow_hub equally hub import tensorflow_datasets as tfds from tensorflow.python import keras from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Embedding, LSTM from sklearn.model_selection import train_test_split from sklearn.metrics import confusion_matrix from sklearn.metrics import classification_report Downloading necessary file
# this cells takes time, delight run once # Carve up the training ready into 60% and twoscore%, and so we'll end upwardly with fifteen,000 examples # for training, 10,000 examples for validation and 25,000 examples for testing. original_train_data, original_validation_data, original_test_data = tfds.load( name="imdb_reviews", dissever=('train[:60%]', 'railroad train[threescore%:]', 'examination'), as_supervised=True) Getting word index from Keras datasets
#tokanizing by tensorflow word_index = tf.keras.datasets.imdb.get_word_index( path='imdb_word_index.json'
)
In [8]:
{k:five for (g,v) in word_index.items() if v < 20} Out[8]:
{'with': 16, 'i': 10, 'as': 14, 'it': ix, 'is': 6, 'in': 8, 'but': xviii, 'of': 4, 'this': 11, 'a': iii, 'for': 15, 'br': 7, 'the': 1, 'was': 13, 'and': 2, 'to': 5, 'film': 19, 'pic': 17, 'that': 12} Positive and Negative Review Comparision

Creating Railroad train, Test Data

Model and Model Summary

Splitting data and fitting the model

Model result Overview

Confusion Matrix and Correlation Report

Annotation: Data Source and Data for this model is publicly bachelor and can exist accessed by using Tensorflow.
For the complete code and details, please follow this GitHub Repository.
In determination, NLP is a field full of opportunities. NLP has a tremendous effect on how to clarify text and speeches. NLP is doing better and better every mean solar day. Knowledge extraction from the large data set up was incommunicable 5 years agone. The rise of the NLP technique made it possible and easy. There are nonetheless many opportunities to discover in NLP.
Source: https://www.analyticsvidhya.com/blog/2020/12/understanding-text-classification-in-nlp-with-movie-review-example-example/
0 Response to "Given a Corpus of a Review Split It in Terms Sentences"
Post a Comment